Mac Mini M4使用LM部署MLX Deepseek
试了一下用LM Studio部署MLX格式的Deepseek-r1-14b-Q4
过程如下:
下载LM Studio Mac版并安装
下载最新的软件版本
下载模型
前往Huggingface或国内镜像搜索deepseek-r1 14b mlx
搜索到的结果内点击files and versions标签,把里面的模型下载下来
安装模型
将下载到的模型保存为这样的路径/A/B/C/,
举例
/MLX/Kevin/Deepseek-r1-14b-Q4/
将上面的A文件夹移动到lmstudio安装路径的/models下
位置一般为/user/.lmstudio/models,
TIP
.lmstudio隐藏文件夹可以使用shift+command+. 显示
隐藏起来是同样的按钮
使用模型
lm studio内load这个模型
lmstudio左下方显示developer,再点击左上的developer标签
开启server,开启setting中的Enable CORS,Local Network,有弹窗则同意
复制显示的API HOST
手机/Mac等客户端使用模型
iOS下载Chatbox AI
设置内选择lmstudio api并将上面的API Host粘贴进去,已经可以选择模型
确认后手机上已经可以使用本地的模型了
个人感受
和ollama比起来,图形界面更友好一些,但下载模型等由于魔法等影响没那么方便。
使用效果上来讲,原理上如下图所示,MLX对Mac来讲更优一些。但实际体验上差距不大。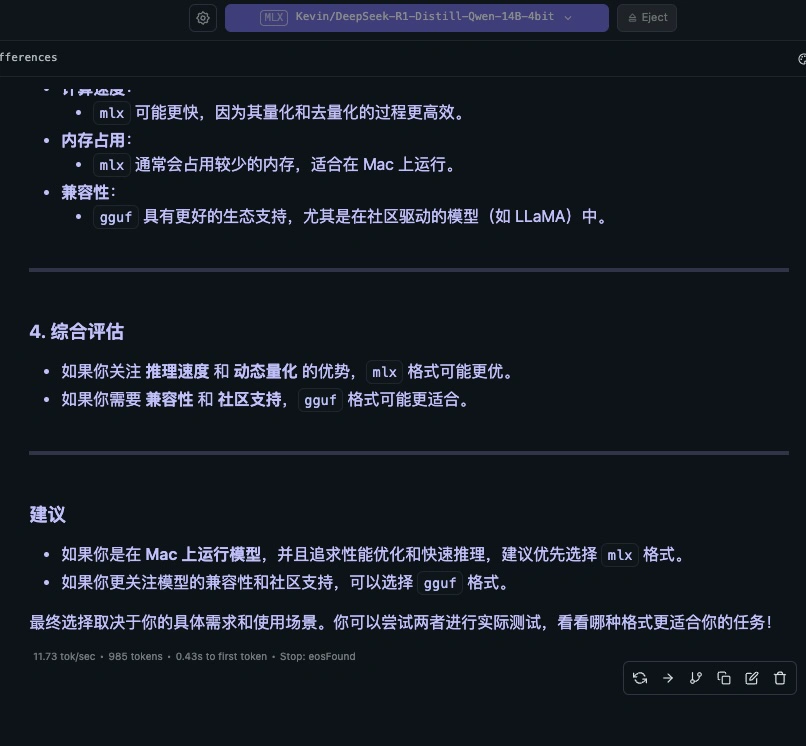
另外,lmstudio在载入模型后不会释放内存,只有eject后才会,模型会常驻内存占用资源。而ollama只在模型被调用时才会。
说明
可能有什么设置我还不知道,也许内存可以主动释放。
但目前总的来说,我还是比较推荐ollama。
Mac Mini M4使用LM部署MLX Deepseek
http://kevinblog.pages.dev/2025/03/20/mlx/